
Many high-growth applications tend to fail to scale not because of traffic, but because their system design cannot adapt as operational complexity increases. As products grow, app development depends less on reacting to traffic spikes and more on building architectures that can adapt without creating operational bottlenecks. Systems built with flexibility in mind are significantly easier to scale over time while maintaining stronger operational stability and development efficiency across teams.
Rapid growth rarely breaks systems without warning. In most cases, the warning signs already exist long before traffic increases. The problem is that many teams lack the visibility required to identify those weaknesses early.
One of the most important priorities in modern system design is observability. Teams cannot scale systems effectively if they cannot monitor performance, identify bottlenecks, or understand how failures spread across infrastructure.
Before traffic increases, organizations should instrument key operational metrics including:
Strong observability allows teams to predict where systems will fail before traffic exposes those weaknesses in production.
Many applications struggle during rapid growth because critical workflows rely too heavily on individual components. Stateful services, tightly coupled dependencies, and synchronous workflows often create operational bottlenecks that become significantly harder to manage as traffic increases.
Successful app development requires identifying these dependencies early so individual failures do not impact the broader platform.
Most scaling failures are not caused by rare infrastructure issues. They usually come from predictable bottlenecks that were never addressed during earlier growth stages.
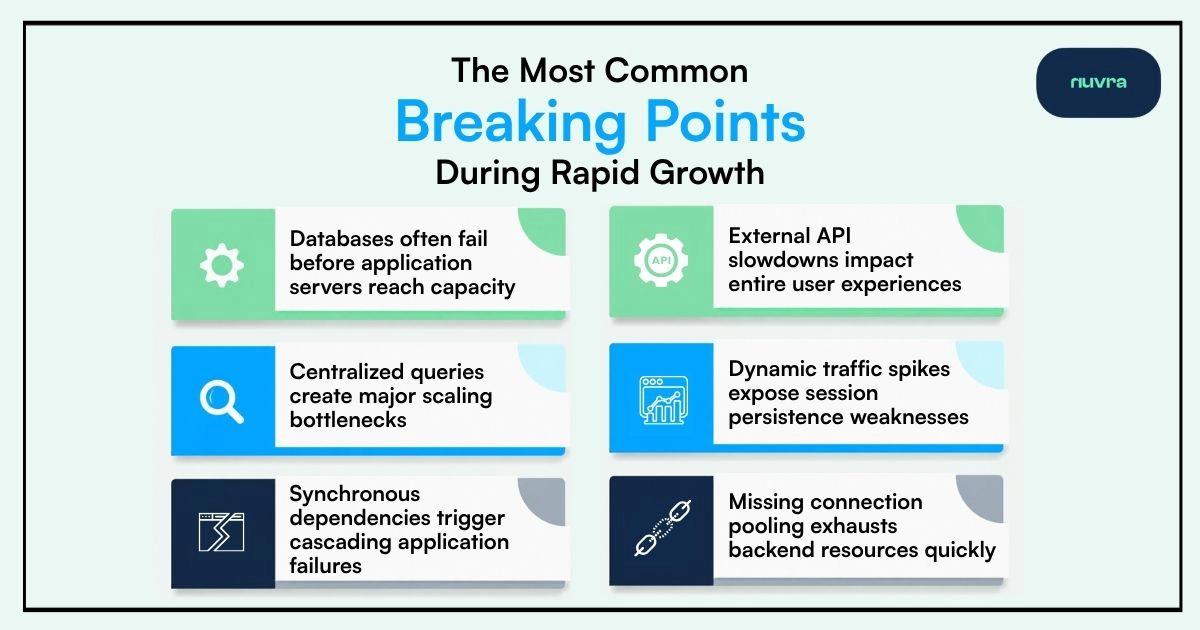
Databases are often the first major failure point during rapid growth. Many teams focus heavily on scaling application infrastructure while overlooking the fact that most requests still depend on centralized database operations.
In many cases, the database layer becomes overloaded long before application servers experience any meaningful strain. Strong system design therefore requires balancing application scalability with database scalability from the beginning.
Third-party APIs and tightly coupled synchronous workflows can create cascading failures during traffic spikes. If external services fail or slow down, entire application flows may become unavailable without proper fallback mechanisms in place.
This becomes particularly dangerous in high-growth environments where small infrastructure delays can quickly impact thousands of simultaneous requests.
Applications relying heavily on in-memory session state often struggle to scale reliably across multiple servers. As infrastructure expands horizontally, maintaining consistent session persistence becomes significantly more difficult.
This creates operational instability during periods of rapid traffic growth, particularly when infrastructure scaling occurs dynamically.
Connection pooling issues are another common scaling bottleneck. Without efficient connection management, databases and backend services can quickly exhaust available resources under high traffic loads.
In many scaling environments, these failures appear suddenly even when overall infrastructure capacity initially seems sufficient.
One of the biggest mistakes organizations make is designing systems that require large-scale architectural changes every time growth increases. Sustainable scalability depends heavily on defining clean boundaries early so individual components can evolve independently.
Successful app development usually means:
When these architectural seams are missing, applications eventually become tightly connected dependency graphs that are difficult to evolve safely under growth pressure.
Scalability almost always requires deliberate operational trade-offs. The most effective systems are not necessarily the most feature-rich or technically sophisticated. They are usually the systems designed around controlled complexity and predictable operational behavior.
Many high-growth platforms prioritize availability at the system edge instead of enforcing strict consistency everywhere. These trade-offs help applications remain operational during periods of heavy traffic or partial infrastructure failure.
Strong system design depends on understanding where consistency matters most and where flexibility creates additional operational resilience.
Asynchronous processing is often introduced for non-critical workflows that do not require immediate execution. This reduces pressure on core infrastructure and improves resilience during traffic spikes.
Instead of forcing every operation through synchronous workflows, scalable systems distribute processing between synchronous and asynchronous workflows more strategically across infrastructure layers.
Overly feature-rich architectures frequently create operational overhead that becomes difficult to maintain during rapid growth. Simpler systems are generally easier to monitor, scale, and evolve as operational demands increase.
Sustainable app development therefore depends heavily on balancing product capabilities with operational simplicity.
Performance optimization becomes dangerous when it is driven primarily by assumptions instead of production data. Many teams introduce unnecessary infrastructure complexity because they optimize hypothetical bottlenecks instead of proven operational problems.
Effective optimization begins with benchmarking, monitoring, and identifying measurable constraints before making architectural changes. This reduces unnecessary complexity while ensuring infrastructure decisions remain aligned with actual operational requirements.
In many cases, strong system design is less about aggressively optimizing every layer early and more about creating architectures flexible enough to evolve as performance demands become clearer over time.
Strong system design allows organizations to handle rapid growth without constant rebuilding or operational instability. Sustainable app development depends on scalable architecture, observability, and controlled complexity. Businesses preparing for high-growth infrastructure can benefit from working with experienced partners like Nuvra.


